운영체제에서의 캐시
성능 향상의 열쇠라고 할 수 있다. 캐시는 현대 운영체제의 성능 최적화에서 중요한 역할을 한다.
프로세서와 메모리 간의 성능 차이를 줄이기 위해 캐시는 설계되고 사용된다.
오늘은 운영체제에서의 캐시의 개념과 중요성, 동작 원리, 그리고 그 유형에 대해 알아봤다.
캐시의 개념
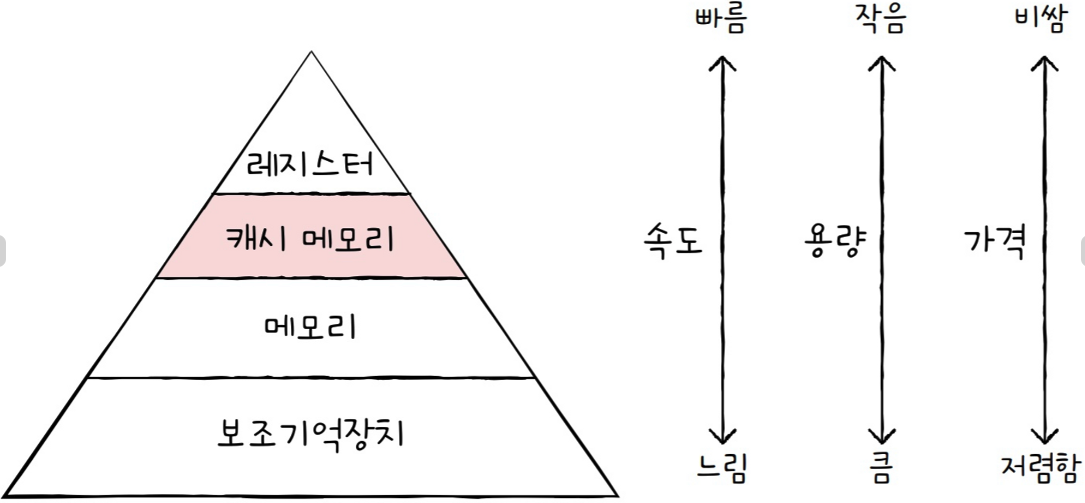
캐시는 데이터를 임시로 저장하는 고속의 작은 메모리 영역이다.
주로 CPU와 메모리 간의 속도 차이를 보완하기 위해 사용된다.
캐시는 CPU에 가까이 위치하여 필요한 데이터를 더 빠르게 제공함으로써 전체 시스템 성능을 향상시킨다.
캐시의 필요성
CPU는 매우 빠른 속도로 작업을 수행하지만, 주기억장치(RAM)는 상대적으로 속도가 느리다.
이 차이로 인해, CPU가 메모리에서 데이터를 불러오는 동안 대기 상태가 될 수 있다.
캐시는 이 속도 차이를 줄여 CPU가 더 많은 작업을 지연 없이 수행할 수 있도록 돕는다.
캐시의 동작 원리
캐시의 동작은 주로 캐시 히트와 캐시 미스라는 두 가지 상황으로 설명된다.
- 캐시 히트 : CPU가 요청한 데이터가 캐시에 존재하여 빠르게 데이터를 반환할 수 있는 상황이다.
- 캐시 미스 : CPU가 요청한 데이터가 캐시에 없는 경우로, 이때 메모리에서 데이터를 가져와 캐시에 저장하고 처리한다.
운영체제는 데이터를 효율적으로 캐시에 배치하기 위해 다양한 알고리즘을 사용한다.
LRU(Least Recently Used), LFU(Least Frequently Used)등의 알고리즘이 대표적이다.
캐시의 유형
운영체제와 CPU는 여러 레벨의 캐시를 사용한다.
- L1캐시 (1차 캐시) : CPU 코어에 가장 가까운 위치에 있으며, 용량은 작지만 속도가 매우 빠르다. 일반적으로 명령어와 데이터를 따로 저장하는 분리형 캐시로 구성된다.
- L2캐시 (2차 캐시) : L1 캐시보다는 크지만 상대적으로 느리다. CPU 코어마다 독립적으로 있거나 코어 간 공유되기도 한다.
- L3캐시 (3차 캐시) : CPU 코어 전체가 공유하는 캐시로, L2보다 큰 용량을 가지고 있으며, 다수의 코어가 함께 사용하는 데이터에 대해 성능을 높인다.
물리적 캐시와 소프트웨어 캐시의 차이점
- 물리적 캐시 (L1, L2, L3)
- 하드웨어 기반: CPU 칩 내부에 내장되어 있음.
- 속도: 메모리보다 훨씬 빠른 접근 속도를 제공.
- 용도: CPU가 데이터를 더 빠르게 가져올 수 있도록 함으로써 프로그램 실행 속도 최적화.
- 자동 관리: CPU가 자체적으로 캐시를 관리하며, 운영체제나 사용자가 이를 직접 제어하지 않음.
- 소프트웨어 캐시 (스프링 캐시, Redis 등)
- 소프트웨어 기반: 애플리케이션 레벨에서 구현되며, 메모리나 디스크 등 다양한 저장소를 사용할 수 있음.
- 속도: 물리적 캐시보다는 느리지만, 데이터베이스나 외부 서비스보다 빠름.
- 용도: 자주 사용되는 데이터를 임시로 저장해 데이터베이스 조회나 네트워크 요청을 줄임으로써 애플리케이션 성능을 최적화.
- 관리 가능: 개발자가 캐시 전략, 만료 시간(TTL), 교체 정책 등을 직접 설정하고 관리할 수 있음.
스프링 캐시: Java와 Spring 프레임워크에서 제공하는 캐싱 추상화로, 다양한 캐시 구현체(Ehcache, Caffeine 등)를 손쉽게 사용할 수 있다. @Cacheable, @CachePut 등의 어노테이션을 통해 특정 메서드의 결과를 캐시에 저장할 수 있다.
Redis: 인메모리 데이터 저장소로, 분산 환경에서 빠른 데이터 접근과 캐싱을 지원한다. 단일 애플리케이션 캐시뿐 아니라 여러 애플리케이션 간 데이터 공유 및 빠른 데이터 접근이 필요할 때 사용된다.
캐시 사용 예시
- 물리적 캐시: CPU가 프로그램의 명령어와 데이터를 더 빠르게 처리하기 위해 사용한다. 프로그램이 CPU에서 실행될 때 필요한 데이터가 L1, L2, L3 캐시 순으로 탐색된다.
- 소프트웨어 캐시: 웹 애플리케이션이 자주 사용하는 데이터를 데이터베이스에 매번 접근하지 않고, Redis나 스프링의 메모리 캐시에 저장해 사용자의 요청에 더 빠르게 응답할 수 있도록 한다.
캐시 지역성
1. 시간 지역성 (Temporal Locality)
- 프로그램이 최근에 접근한 데이터는 가까운 시일 내에 다시 접근할 가능성이 높다는 특성
- 반복분에서 동일한 변수를 계속 사용하는 경우가 대표적(루프에서 변수 i가 반복 사용되면 i는 캐시에 남아 있어 이후 접근이 빠르게 이루어진다.)
- 데이터가 캐시에 남아 있어 CPU가 메모리에 다시 접근할 필요 없이 빠르게 데이터를 가져올 수 있다.
2. 공간 지역성 (Spatial Locality)
- 프로그램이 특정 메모리 위치에 접근하면, 근처 메모리 위치에도 곧 접근할 가능성이 높다는 특성
- 배열이나 연속된 데이터 구조를 순차적으로 읽는 경우
- 캐시는 데이터 블록 단위로 데이터를 저장하여, 한 번 가져온 데이터가 다음에 필요한 데이터를 포함할 가능성이 높아 효율적이다.
지역성과 캐시 설계의 연관성: 캐시 메모리는 지역성의 원리를 최대한 활용하도록 설계된다.
- 블록 단위로 데이터 전송: 캐시는 데이터를 가져올 때 특정 메모리 주소뿐만 아니라 인접한 데이터를 함께 가져와 공간 지역성을 활용한다.
- 캐시 교체 정책: LRU(Least Recently Used) 같은 교체 정책은 시간 지역성을 잘 활용하여, 가장 오랫동안 사용되지 않은 데이터를 교체하도록 설계된다.
'CS 지식 > 운영체제' 카테고리의 다른 글
| [운영체제] 운영체제 동기화 방법: 세마포어와 뮤텍스 (0) | 2024.09.21 |
|---|---|
| [운영체제] 프로세스와 스레드 (0) | 2024.08.02 |
| [운영체제] 메모리 계층 구조 (0) | 2024.06.21 |
| [운영체제] PCB(Process Control Block)란? (0) | 2024.05.17 |


